비최대값 억제 (NMS) 알고리즘
본 포스트에서는 영상 처리 및 객체 검출에서 흔히 사용되는 비최대값 억제(Non maximum supression) 알고리즘에 대해서 설명하겠습니다.
캐니 엣지
비최대값 억제 알고리즘은 국지적인 최대값을 찾아 그 값만 남기고 나머지 값은 모두 삭제하는 알고리즘입니다. 가장 단순한 사용례로는 OpenCV에서도 지원하는 외곽선 검출 알고리즘인 캐니 엣지(Canny Edge) 알고리즘이 있습니다.
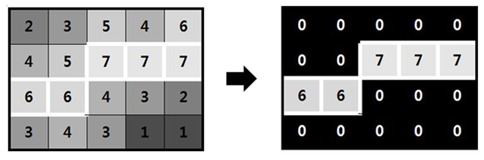
캐니 엣지 알고리즘에서는 가우시안 필터와 소벨 마스크를 거쳐서 나온 색상 변화량 데이터에서 윤곽을 찾아내기 위해 비최대값 억제 알고리즘을 사용합니다. 특정 픽셀의 주변 값이 그 픽셀의 값과 큰지 작은지 검사하고, 현재 픽셀보다 큰 주변 값이 있으면 해당 값을 삭제합니다. 이 과정을 거쳐 색상 변화량의 국소 극값을 구할 수 있으며 색상 변화량이 최대가 되는 부분에 외곽선이 존재할 가능성이 높다고 판단할 수 있습니다.
객체 검출
객체 검출에서는 중복 발생하는 경계 상자를 제거하기 위해 비최대값 억제 알고리즘을 사용합니다. 이 경우에는 경계 상자가 물체일 확률을 기준으로 비교하며, 비교 대상이 주변 픽셀이 아니라 자신과 겹친 영역이 일정 값 이상인 경계 상자가 됩니다.
비최대값 억제 알고리즘의 코드를 보면서 하나씩 하나씩 원리를 설명하겠습니다.
import numpy as np
def non_max_suppression_slow(boxes, probs, overlap_thresh):
boxes는 경계 상자의 정보를 담은 2차원 넘파이(NumPy) 배열, probs는 각 상자의 확률을 담은 1차원 넘파이 배열입니다. overlap_thresh는 두 경계 상자가 어느 정도 겹쳐져 있으면 비최대값 억제의 대상으로 할 것인지를 판단하기 위한 임계값이며 0보다 크고 1보다 같거나 큰 실수입니다.
if not boxes.size:
return np.empty((0,), dtype=int)
pick = []
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
area = (x2 - x1) * (y2 - y1)
idxs = np.argsort(probs)
먼저 각 경계 상자의 넓이를 구합니다. 각 경계 상자의 x1, y1, x2, y2 값을 배열로 추출한 다음에 요소별(element-wise) 연산을 통해 각 경계 상자의 넓이를 갖는 배열을 만듭니다. 그리고 확률 값을 오름차순 정렬한 다음에 그 정렬 결과의 배열 인덱스를 담은 배열을 idxs라는 이름으로 저장합니다.
while idxs.size:
last = len(idxs) - 1
i = idxs[last]
pick.append(i)
suppress = [last]
idxs 배열 안의 요소 중 가장 마지막의 원소는 확률값이 가장 큰 경계 상자의 인덱스입니다. 이 인덱스를 추출하여 pick 리스트에 넣습니다.
for pos in range(last):
j = idxs[pos]
xx1 = max(x1[i], x1[j])
yy1 = max(y1[i], y1[j])
xx2 = min(x2[i], x2[j])
yy2 = min(y2[i], y2[j])
w = max(0, xx2 - xx1)
h = max(0, yy2 - yy1)
overlap = (w * h) / area[j]
if overlap > overlap_thresh:
suppress.append(pos)
이제 방금 선택한 경계 상자를 제외하고 나머지 경계상자를 전부 순회하면서 현재 경계상자와 겹친 영역의 넓이 비율(overlap)을 구하고, 이 비율이 임계값(overlap_thresh)보다 크면 해당 경계 상자의 인덱스를 suppress 리스트에 등록합니다.
idxs = np.delete(idxs, suppress)
return boxes[pick], probs[pick]
순회가 끝나면 현재 경계상자와, 이 경계상자보다 확률이 낮으면서 일정 비율 이상 겹쳐있는 모든 상자가 suppress 리스트에 포함되게 됩니다. suppress 리스트에 포함된 모든 상자를 idxs로부터 제거하고, 위 작업을 idxs에 더이상 남은 요소가 없을 때까지 반복합니다. 이 작업이 끝나면 pick 리스트에는 억제되지 않은 경계 상자의 인덱스만 남아있게 됩니다. boxes 상자에서 pick 리스트에 존재하는 경계 상자만 추출하여 반환합니다.
최적화
위 코드는 이해하기 쉽지만 속도가 매우 느립니다. 실제로 최신의 인텔 스카이레이크 Core i5 시스템에서 100만개의 경계 상자를 처리하는 데 2분 이상이 걸립니다. 위 코드에서 안쪽 for 루프를 넘파이 라이브러리를 이용 벡터화(vectorize)시키면 속도를 크게 향상시킬 수 있습니다. 아래 코드는 벡터화된 알고리즘이며 위 코드보다 수십배 가량 빠릅니다. Keras 기반 F-RCNN의 원리에서 소개한 F-RCNN 코드에서도 별도로 언급하진 않았지만 같은 알고리즘을 사용하고 있습니다. 원리 자체는 위 코드와 동일하므로 설명은 생략하겠습니다.
import numpy as np
def non_max_suppresssion_fast(boxes, probs, overlap_thresh):
if not boxes.size:
return np.empty((0,), dtype=int)
if boxes.dtype.kind == 'i':
boxes = boxes.astype('float')
pick = []
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
area = (x2 - x1) * (y2 - y1)
idxs = np.argsort(probs)
while idxs.size:
last = len(idxs) - 1
i = idxs[last]
pick.append(i)
xx1 = np.maximum(x1[i], x1[idxs[:last]])
yy1 = np.maximum(y1[i], y1[idxs[:last]])
xx2 = np.minimum(x2[i], x2[idxs[:last]])
yy2 = np.minimum(y2[i], y2[idxs[:last]])
w = np.maximum(0, xx2 - xx1)
h = np.maximum(0, yy2 - yy1)
overlap = (w * h) / area[idxs[:last]]
idxs = np.delete(idxs, np.concatenate(([last], np.where(overlap > overlap_thresh)[0])))
return boxes[pick].astype('int'), probs[pick]