Keras 기반 F-RCNN의 원리
본 포스트에서는 Keras 기반으로 구현한 Faster RCNN 코드와 함께 알고리즘의 원리에 대해서 해설하겠습니다.
모델의 원리
RCNN은 기존의 신경망 기반 딥러닝 객체검출 알고리즘에 합성곱 신경망(CNN; Convolutional Neural Network)을 적용하였습니다. RCNN 알고리즘은 다음과 같은 순서로 객체 검출을 수행합니다.
- 이미지 내에 객체가 존재하는 적절한 위치를 제안
- 제안된 위치의 이미지를 잘라냄
- 잘라낸 이미지의 특징 지도(feature map)를 추출
- 특징 지도를 분류기에 입력하여 분류
여기서 CNN을 3, 4번 차례에 도입하여, 특징 지도를 추출하고 분류하는데 CNN을 사용합니다. RCNN은 기존 알고리즘 대비 정확도가 향상되긴 했지만 속도가 느려 실시간 객체 검출에 사용하기에는 한계가 있었습니다. 그래서 Fast/Faster RCNN이라는 개선안이 나오게 됩니다.
Fast RCNN에서는 3, 4번 과정의 병목을 개선하였습니다. 잘라낸 영역마다 CNN을 적용하는 대신, 이미지 전체를 CNN에 통과시켜 큰 특징 지도를 구하고 제안된 영역을 특징 지도에 투영하도록 하였습니다. 이 개선을 통해 특징 지도를 추출하는 CNN 과정이 단 1번만 처리하도록 개선되어 속도가 크게 향상되었습니다. 또한 RoI pooling layer를 도입하여 잘라낸 특징 지도 영역을 고정 길이의 특징 정보로 변환하도록 하여 분류 모델의 구성이 단순해지는 효과를 얻었습니다.
이 포스트에서 소개할 모델은 Faster RCNN이며, Fast RCNN을 다시 한번 개선한 모델입니다. Faster RCNN은 1번 과정의 병목을 개선하였습니다. 영역 제안망(region proposal network)을 신설하여 영역 제안에도 CNN을 사용합니다. 또한 영역 제안망에서 특징 지도를 추출하기 위해서 사용하던 신경망을 일부 공유하도록 하면 영역 제안을 위해 사용하는 추가 계산 비용을 크게 줄일 수 있습니다. 이 개선에 따라 예측 속도 향상은 물론이고 정확도가 상승하였습니다. Faster RCNN은 RCNN 대비 정확도는 향상되었으면서 속도를 동영상의 준-실시간 처리가 가능한 수준까지 끌어 올렸습니다.
훈련 샘플의 구성
해당 코드에서는 simple_parser.py와 pascal_voc_parser.py의 두 가지 파서를 제공합니다.
pascal_voc_parser.py는 PASCAL VOC Dataset의 규격에 맞춰 데이터셋을 파싱합니다. PASCAL VOC Dataset은 모델 루트 폴더 안의 Annotations 폴더 안의 xml 파일들이 이미지의 레이블을 제공하고, JPEGImages 폴더 안에 실제 이미지가 존재하여 이 둘이 대응됩니다. PASCAL VOC Dataset은 객체 안의 부위 분류(예컨대 사람 객체 안의 머리, 손, 다리)와 이미지 분할을 위한 분류도 제공하지만 이 코드는 단순 객체 검출이라 사용하지 않습니다. xml 파일의 일부를 소개하면 다음과 같습니다.
<annotation>
<folder>VOC2012</folder>
<filename>2007_000027.jpg</filename>
<!-- 중략 -->
<object>
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>174</xmin>
<ymin>101</ymin>
<xmax>349</xmax>
<ymax>351</ymax>
</bndbox>
<!-- 후략 -->
folder와 filename 태그를 통해 대응되는 이미지를 지정하며, object 태그는 해당 이미지 안의 객체 하나를 의미합니다. name 태그로 객체의 종류를 지정하며 bndbox 태그로 객체의 위치를 지정합니다.
simple_parser.py는 좀 더 단순한 태깅 방법을 제공합니다. 한 줄에 객체 하나씩, 콤마로 구별하여 파일이름, 객체 위치, 객체 종류를 서술합니다. 위 PASCAL VOC 태그를 simple_parser의 방식으로 서술하면 다음과 같습니다.
2007_000027.jpg,174,101,349,351,person
모델의 구성
Faster R-CNN은 Fast R-CNN 대비, 영역 제안을 딥러닝 모델을 통한 방법으로 변경하여 성능 향상을 달성하였습니다. 기반 CNN 모델은 기본값으로는 ResNet50을 사용하며 (원본 논문에서도 ResNet50을 사용하였습니다) VGG16을 대신 사용할 수 있는 기능도 제공합니다.
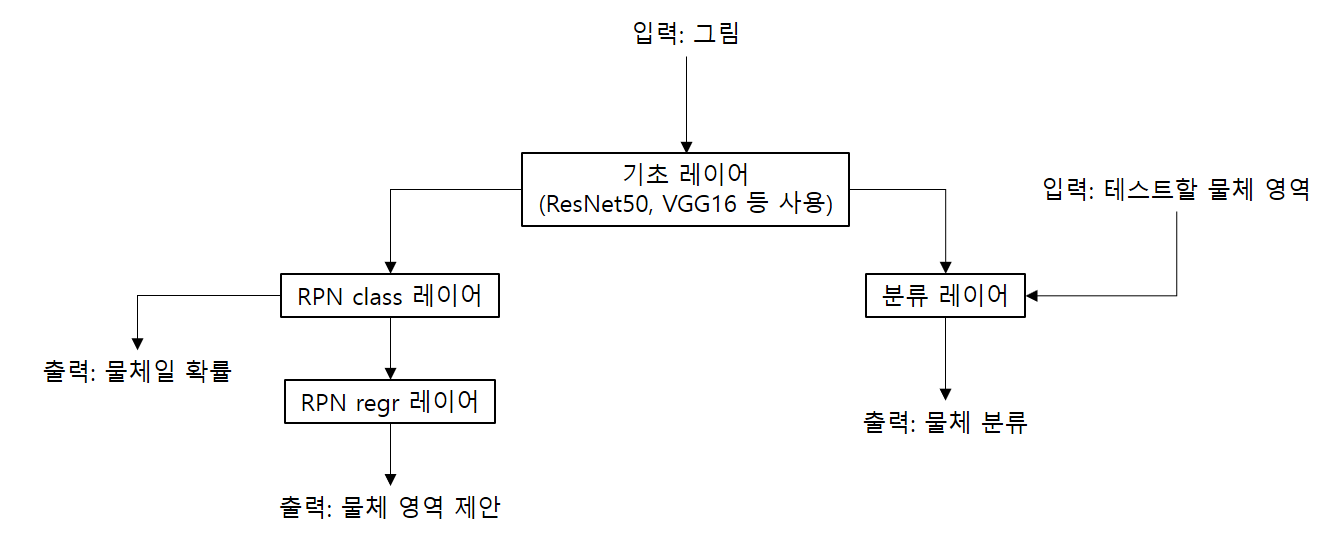
모델의 구성은 위와 같습니다. 입력값은 물체를 검출할 대상 이미지이며, 출력값은 물체가 존재할 확률 지도, 물체 분류 2가지와 그 회귀(regression) 값 4가지로 구성됩니다. 이 모델을 한번에 가동하는 것이 아니라 모델을 여러 단계로 분할하여 단계적으로 훈련 및 예측이 실행되게 됩니다.
# define the base network (resnet here, can be VGG, Inception, etc)
shared_layers = nn.nn_base(img_input, trainable=True)
# define the RPN, built on the base layers
num_anchors = len(C.anchor_box_scales) * len(C.anchor_box_ratios)
rpn_layers = nn.rpn(shared_layers, num_anchors)
classifier = nn.classifier(feature_map_input, roi_input, C.num_rois, nb_classes=len(class_mapping), trainable=True)
model_rpn = Model(img_input, rpn_layers)
model_classifier = Model([feature_map_input, roi_input], classifier)
print('Loading weights from {}'.format(C.model_path))
model_rpn.load_weights(C.model_path, by_name=True)
model_classifier.load_weights(C.model_path, by_name=True)
model_rpn.compile(optimizer='sgd', loss='mse')
model_classifier.compile(optimizer='sgd', loss='mse')
이 코드는 모델을 구성하는 과정입니다. shared_layers는 기반 레이어를 의미하며 옵션에 따라 다른 기반 CNN 모델이 사용됩니다. (resnet.py 또는 vgg.py) 기반 모델은 특징 지도를 추출하기 위해 사용됩니다.
model_rpn은 특징 지도로부터 관심 영역(region of interest)를 구하는 영역 제안망이며 위 그림의 왼쪽 부분에 해당합니다.
model_classifier는 특징 지도와 관심 영역을 입력으로 받아 영역 내의 이미지를 분류하는 분류기이며, 위 그림의 오른쪽 부분에 해당합니다.
훈련과 예측
img = cv2.imread(filepath)
X, ratio = format_img(img, C)
if K.image_dim_ordering() == 'tf':
X = np.transpose(X, (0, 2, 3, 1))
# get the feature maps and output from the RPN
[Y1, Y2, F] = model_rpn.predict(X)
R = roi_helpers.rpn_to_roi(Y1, Y2, C, K.image_dim_ordering(), overlap_thresh=0.7)
위 코드는 입력값을 받아 관심 영역을 추출하는 과정입니다. 이해하기 쉽게 예시로 1280*960px의 크기를 갖는 이미지가 입력값으로 들어왔다고 가정하겠습니다. 먼저 입력값을 그림으로 받아 rpn class에서 물체인지 아닌지의 확률이 출력되도록 합니다. 입력 이미지는 짧은 쪽의 해상도가 600px이 되도록 조정됩니다. 1280*960px 해상도를 가진 이미지라면 800*600px으로 조정됩니다. 그리고 이 이미지를 16*16px의 블럭으로 분할하는데, 각 블럭별로 물체일 확률이 추출됩니다. rpn class 레이어에서 출력하는 값은 각 블럭별로 물체가 존재할 확률을 갖는 50*38 크기의 배열이 되며 위 코드에서는 Y1에 해당합니다. Y2는 영역 미세 조정에 사용되는 회귀값이며 F는 기반 레이어의 출력값입니다.
이 확률 배열을 이용해서 관심 영역을 추출하게 되는데, 이 과정은 rpn_to_roi 함수가 실행합니다.
def rpn_to_roi(rpn_layer, regr_layer, C, dim_ordering, use_regr=True, max_boxes=300,overlap_thresh=0.9):
regr_layer = regr_layer / C.std_scaling
anchor_sizes = C.anchor_box_scales
anchor_ratios = C.anchor_box_ratios
# 중략
for anchor_size in anchor_sizes:
for anchor_ratio in anchor_ratios:
anchor_x = (anchor_size * anchor_ratio[0])/C.rpn_stride
anchor_y = (anchor_size * anchor_ratio[1])/C.rpn_stride
# 중략
curr_layer += 1
all_boxes = np.reshape(A.transpose((0, 3, 1,2)), (4, -1)).transpose((1, 0))
all_probs = rpn_layer.transpose((0, 3, 1, 2)).reshape((-1))
# 중략
result = non_max_suppression_fast(all_boxes, all_probs, overlap_thresh=overlap_thresh, max_boxes=max_boxes)[0]
return result
그리고 각 블럭에 대해서, 그 블럭을 중심으로 비율이 1:1 또는 가로 또는 세로가 긴 2:1 비율인 3가지 비율, 짧은 길이가 8블럭인 경우, 16블럭인 경우, 32블럭인 경우인 3가지 크기로 영역을 추출합니다. 추출할 영역의 비율과 크기는 위 코드에서 anchor_box_scales와 anchor_box_ratios에 정의되어 있습니다. 이 과정을 거치면 각 블럭당 9개의 영역이 추출되어 총 17100개의 영역이 나옵니다. 당연히 모든 영역에 대해서 분류를 실행할 수는 없는 만큼 가능성이 높은 경계 상자만 남겨야 합니다. 이를 위해 각 영역 내의 물체 확률 중 가장 높은 값을 해당 영역에 물체가 존재할 확률로 간주하고 비최대값 억제(NMS) 알고리즘을 사용합니다. 이때 300개 초과 영역이 남은 경우 물체 존재 확률이 낮은 초과 분량을 모두 제거하고 상위 300개의 영역만을 반환합니다.
[P_cls, P_regr] = model_classifier_only.predict([F, ROIs])
for ii in range(P_cls.shape[1]):
if np.max(P_cls[0, ii, :]) < bbox_threshold or np.argmax(P_cls[0, ii, :]) == (P_cls.shape[2] - 1):
continue
cls_name = class_mapping[np.argmax(P_cls[0, ii, :])]
if cls_name not in bboxes:
bboxes[cls_name] = []
probs[cls_name] = []
(x, y, w, h) = ROIs[0, ii, :]
# 중략
bboxes[cls_name].append([C.rpn_stride*x, C.rpn_stride*y, C.rpn_stride*(x+w), C.rpn_stride*(y+h)])
probs[cls_name].append(np.max(P_cls[0, ii, :]))
all_dets = []
for key in bboxes:
bbox = np.array(bboxes[key])
new_boxes, new_probs = roi_helpers.non_max_suppression_fast(bbox, np.array(probs[key]), overlap_thresh=0.5)
이제 많아도 300개의 관심 영역이 남았습니다. 이제 위 그림 오른쪽의 분류 레이어를 사용합니다. 분류 모델의 입력값은 1) 기초 레이어의 출력값 2) 테스트할 물체 영역 두가지가 있는데, 전자는 이미 관심 영역을 구할 때 구했으니 다시 계산할 필요 없이 그 값을 그대로 사용할 수 있습니다. 후자는 관심 영역의 left, top, right, bottom 값 4개를 사용합니다. 분류 레이어의 출력은 보통의 이미지 분류 문제와 같이, 클래스 갯수만큼의 각 클래스일 확률이 구해집니다. 가장 확률이 높은 클래스를 선택한 다음, 확률이 임계값 이하인 클래스를 제거하고 클래스가 같은 경계 박스끼리 비최대값 억제를 하는 등의 후처리를 통해 사람이 확인할 수 있는 최종 결과를 얻어내게 됩니다.